【分享】审稿人拷问:你控制混杂因素了吗?我:…
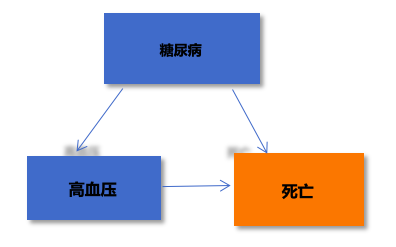
高高兴兴地写完一篇 SCI,投稿,苦苦等待好久,却只等来审稿人的一句话:你有控制研究的混杂因素(Confounder)吗?今天,笔者就从「什么是混杂因素」、「为什么要控制混杂因素」以及「该如何控制混杂因素」,这三方面来分享一下。混杂因素,指的是除了研究因素以外,其他所有可能会影响结局的因素(包括已知和未知的)。混杂因素与结局事件、暴露/处理因素有关,但不是暴露/处理因素与结局事件的中间变量。如,研究高血压与死亡风险之间的关系。糖尿病就可作为其混杂因素,糖尿病与高血压、死亡都可能有关,但不可以说高血压导致糖尿病从而引起死亡。保证研究结果的真实性与可靠性,就是控制混杂因素的最大意义。为什么 RCT 的证据等级比观察性研究高?一个重要的原因就是 RCT 通过随机分组,有效的控制了混杂因素,减少了混杂偏倚,使得组间的基线情况均衡。分层分析是最为常见的,也是最容易理解的一种控制混杂的方式。3)若一致,比较合并后的效应值与原始的效应值之间是否有统计学意义;需注意,分层分析与亚组分析略有不同,亚组分析不计算合并后的效应值,主要是对比分层之间的效应值。一般只能针对一个混杂因素进行分析,混杂因素过多时,会产生过多分层,导致每层之间的样本量太少,降低结果的可靠性。所以,不适合过多混杂因素时使用。多因素分析能够同时分析多个因素对结局的影响。最常使用的三种回归模型为:多重线性回归、logistic 回归及 Cox 回归。1)既然有多因素分析,是不是可以把全部的混杂因素都纳入多因素分析?纳入混杂因素越多,所需要的结局事件例数就越多,对于 logistic 回归和 Cox 回归,结局事件则应至少为 15-20 倍的自变量个数。建议最好分析前尽量明确哪些可能是混杂因素,而不是一股脑的全分析。2)可以把单因素分析中 P 值小于 0.05 的自变量全纳入多因素分析吗?若 P 值小于 0.05 的自变量数量不多,且结局事件够多,可以这样操作。若结局事件不多,P 值小于 0.05 的自变量数量又比较多,建议将临床意义大、与结局事件密切相关的因素纳入分析。Cox 回归用于二分类变量和生存时间变量(预后分析),logistic 回归用于分类变量,多重线性回归用于连续变量。简单来说,就是将多个混杂因素进行处理,计算出一个综合的倾向值(Propensity Score, PS),然后根据这个倾向值进行匹配。该方法的优势在于用一个综合的分值来替代多个混杂因素,减少自变量个数,克服分层分析和多因素分析中对于自变量数量的限制。本人是将其理解为高考总分,计算语数英+文综/理综的总分,然后找一个总分相近的人进行匹配,比较的是综合的分数,而不是每一科的分数。这里面还有一个重要的概念就是卡钳值(Caliper),即 PS 相差多少以内可以进行匹配。卡钳值越大,匹配成功的数量越多,但是组间均衡性会变弱。反之,卡钳值越小,组间均衡性会增强,但匹配成功的数量越少。合适的卡钳值一般为 0.02 或 0.03(并不是绝对的)。匹配的比例一般为 1:1 或 1:2。除了上述传统的倾向性评分匹配以外,还有三种高阶版的方法:倾向性评分分层法、倾向性评分校正法、倾向性评分加权法。这里就不予详细介绍了。有了分层分析、多因素分析及倾向性分析这三大法宝,再也不用担心混杂因素的干扰了。